
A few years ago, I built an Apache Spark-based analytics engine for a major financial institution. It was supposed to be the ultimate solution—one engine to rule them all, capable of handling every use case.
But reality hit fast. The first use case we tackled was small-scale and didn’t fit Spark at all. That’s when I realized:
🚫 There is no "one-size-fits-all" data processing engine.
✅ Flexibility is the key—different tools for different jobs.
Fast forward to today, we’re delivering AI-driven Data Products and Digital Twins, and we need to do this at scale, with speed, and full transparency.
The Problem: Why Do Organizations Keep Trying to Force One Tool for Everything?
Many organizations default to a single monolithic data processing tool. They then document what's in there and hope that cataloging data will solve their challenges.
🔹 This slows innovation.
🔹 It forces use cases to fit the tool, rather than choosing the right tool for the use case.
🔹 It creates friction for AI, which requires different models and data formats (LLMs, classical ML, graph, metrics, pipelines, etc.).
We take the opposite approach!
A Better Way: Business-First, Processing-Last
At Dataception, we start with the business process, not the data.
1️⃣ Define the End-to-End Business Process
- We use AI + Agentic methods to accelerate this.
- The process is modeled as a Data Object Graph (DOG).
2️⃣ Spin Up Data Products
- These contain their own data structures and processing engines (Python, LLMs, ML models, pipelines, metrics, etc.).
- Each Data Product is built for its specific job, rather than being forced into a monolithic system.
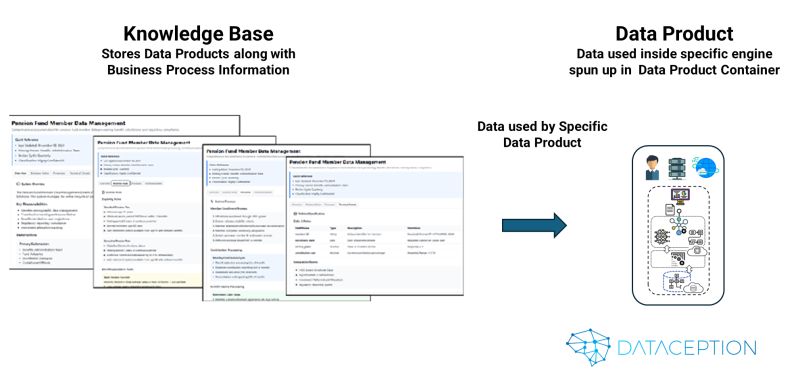
3️⃣ Capture Everything in a Knowledge Base
- Instead of traditional cataloging, we document:
✅ How the data is used
✅ How the analytics work
✅ How the business process functions - This connects business and technical users seamlessly.
Think of It Like Kaggle for Your Organization
Imagine Kaggle:
- The competition is the top-level business problem.
- The entries are Data Products that contain:
✅ Datasets
✅ Models
✅ Pipelines
✅ Discussions, documentation, and all relevant artifacts
Now apply that to your business data.
Instead of dumping everything into one system, each Data Product:
✔️ Lives in a business context
✔️ Is clearly documented
✔️ Can be adopted, built upon, or ignored based on use case
✔️ Can be executed independently or as part of an end-to-end business process
And because processing is separate from knowledge, data users can:
🔹 Browse the Knowledge Base to see what’s available and how it’s used
🔹 Decide whether to use an existing Data Product or create a new one
🔹 Run and transform data with the right processing engine for their needs
The Outcome: Business Agility, AI-Ready Data, and Unmatched Speed
✅ Organizations gain business-level knowledge of their data—directly linked to business processes.
✅ AI and analytics teams can move faster, selecting the right processing tools instead of being boxed into one system.
✅ Massive flexibility to work with different models, tools, and data structures.
✅ GenAI can accelerate the entire process—from defining use cases to spinning up Data Products.
This is how we build Data Products at Dataception, and it’s why we can transform businesses at unprecedented speed.
What’s Your Experience?
Are you still stuck in the “one tool to rule them all” mindset, or are you already shifting to a more dynamic, flexible approach?
Drop us your thoughts, get in touch and see how we can help you.
With Dataception's DOGs (Data Object Graphs), AI is just a walk in the park.