Data Object Graphs (DOGs) unify data and processes into a single, scalable framework, empowering organizations to turn raw data into actionable insights. By combining advanced analytics with intelligent automation, DOGs streamline workflows and enable rapid, reliable decision-making. Discover how this innovative approach bridges traditional analytics with the evolving demands of AI, delivering efficiency and scalability at every stage of the data lifecycle.
In today's rapidly evolving technological landscape, traditional data processing models are being challenged by the complexities of modern business processes and the demands of artificial intelligence (AI) applications. Directed Acyclic Graphs (DAGs) have long been the backbone of data pipelines and orchestration tools. However, as AI systems increasingly rely on feedback loops and complex data structures, there's a growing need for more sophisticated models.
This article introduces the concept of Data Object Graphs (DOGs), a hybrid data and execution graph model designed to address the limitations of DAGs. Developed by Dataception Ltd, DOGs blend data and execution nodes to create queryable, adaptable, and traversable graphs suitable for both AI and traditional analytics use cases. By integrating methods and state within nodes, DOGs offer a dynamic and executable framework that mirrors intricate business processes, supports AI agents, and handles complex data types.
We will explore how DOGs are revolutionizing data and AI development across various parts:
By delving into these topics, we aim to showcase how DOGs provide a robust foundation for modern data processing needs, enabling organizations to innovate rapidly while minimizing risks and costs. Whether you're a data scientist, AI practitioner, or business leader, understanding DOGs could be the key to unlocking new potentials in your data and AI initiatives.
In light of the recent session by Daniel Svonava, Colleen Tartow, Ph.D., and Tobias Macey—where Daniel declared, "DAG is dead" and explained that "AI doesn't work in neat straight lines—it thrives on feedback loops"—we felt compelled to share insights into a core innovation we've been developing at Dataception Ltd as part of an upcoming significant initiative.
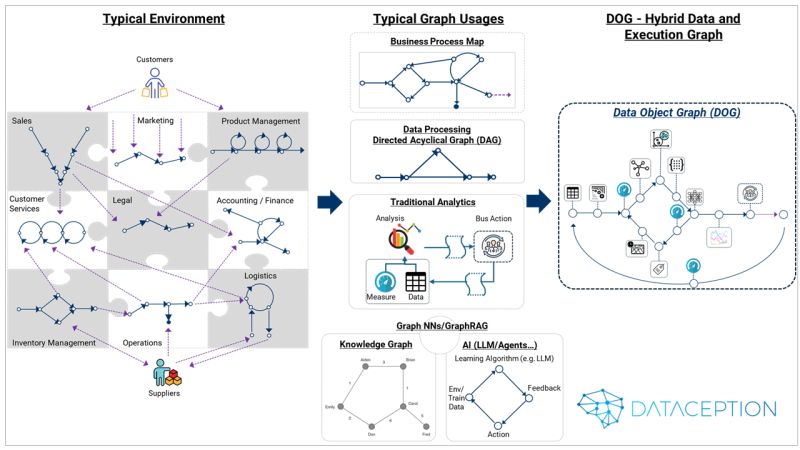
Graphs are gaining prominence, and it's about time. Jon Cooke implemented his first graph solution a decade ago, but as a coder, he has been implicitly utilizing graphs of the Object-Oriented Design/Object-Oriented Programming (OOD/OOP) variety for over 30 years. The object graph model forms the foundation for these systems, along with their compilers and linkers.
Graphs are ubiquitous. A typical organization has numerous graphs representing their business processes. In data and AI development, we use pipelines (linear graphs), trees, and the widely adopted Directed Acyclic Graphs (DAGs) to orchestrate pipelines. Tools like Spark, Airflow, and many other data platforms base their entire processing models on DAGs.
DAGs are acyclic, meaning they do not loop back on themselves. However, business processes often are not acyclic; they include loops and backtracks. Furthermore, the AI world is replete with cycles—in training, reinforcement learning used by classical AI, Large Language Models (LLMs), agents, Retrieval-Augmented Generation (RAG), Graph Neural Networks, and more.
To handle these complex flows, we need something more sophisticated. Other types of graphs, such as knowledge graphs, are beneficial but only provide part of the solution. Additionally, we now deal with complex data structures—embeddings, images, videos, multi-modal data—as opposed to traditional relational data. Coupled with AI agents that require access to data and runnable components to process actions, existing graph paradigms are insufficient.
Enter the Data Object Graph (DOG). DOGs are a blend of data and execution; the nodes can be various types of objects in the true sense of OOD/OOP. They can contain data (state) and methods (functions) that can be executed upon traversal.
At Dataception Ltd, we have been pioneering a solution that leverages DOGs for years. We are extremely excited about this development, as we believe it is the missing piece in approaches like the Data Mesh, Data Fabric, and AI.
DOGs build upon foundational technologies such as Service-Oriented Architecture (SOA), OOD/OOP, and risk models (which are essentially large execution graphs). However, they require not only a new technical processing model but also a new Rapid Application Development (RAD) style design language. This language brings together use cases and data to quickly and iteratively map out end-to-end business use cases that visually mirror the business processes being modeled.
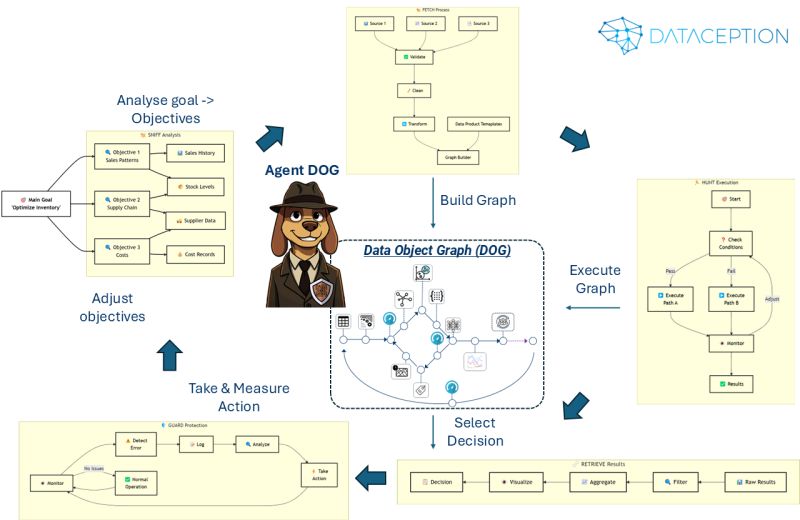
Many have asked how AI agents interact with Data Object Graphs (DOGs). To explain this concept without delving into complex technical jargon, let's introduce a character: Agent DOG.
Agent DOG is an AI agent that systematically breaks down and solves problems by creating and following interconnected paths through data and analytics business processes. Much like a well-trained dog following a scent trail, Agent DOG begins with a clear goal, identifies the essential components needed to achieve that goal, and then constructs a map illustrating how all these pieces connect and flow together.
The AI agent creates and navigates the DOG carefully and methodically. It verifies its work at each step, adjusts its path when necessary, and learns from experience to make better decisions in the future. If it encounters an issue, it can backtrack to determine what went wrong and how to fix it.
To extend the analogy further, here is a breakdown of Agent DOG's problem-solving approach:
Instead of relying on rigid analytics pipelines that break when conditions change, this approach provides an AI system that continuously adapts its analysis paths based on practical effectiveness. It catches problems early and refines its methodology with each decision made.
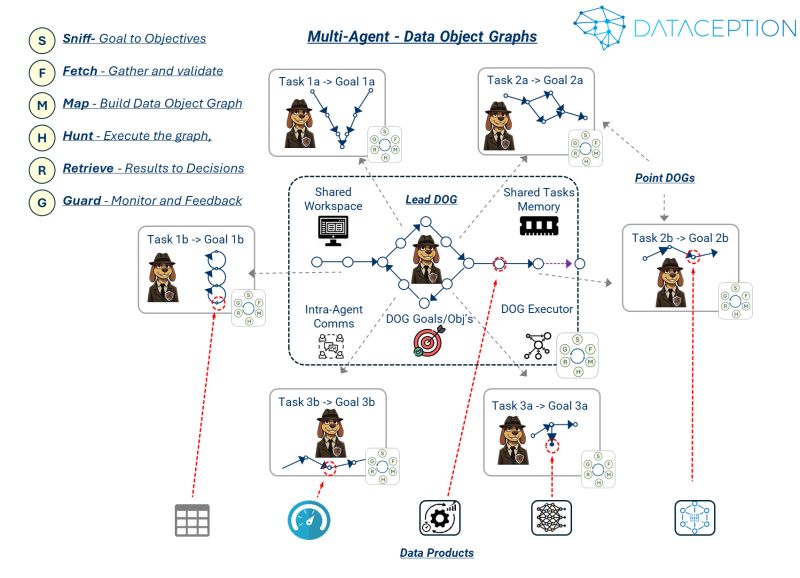
"Who Let the DOGs Out?": the diagram below illustrates how Agent DOGs collaborate. Agent DOGs are AI agents operating over a Data Object Graph, each with its own goals, objectives, and tasks executed over their respective graphs.
They all follow the same process: SNIFF ➔ FETCH ➔ MAP ➔ HUNT ➔ RETRIEVE ➔ GUARD
We have an overall Agent DOG that maps to the overarching goal but decomposes into sub-Agent DOGs, each with its own goals and objectives. The entire process operates in a shared workspace where all Agent DOGs share the environment, access, and exchange data using shared memory but communicate over a shared messaging communication system.
Each Agent DOG is initiated and coordinated by the Lead Agent (borrowing terminology from sled dog teams). The lead agent owns, creates, and executes its graph overall, but each Point Agent is defined and activated by the lead agent, operating within its own execution space while interacting with the shared workspace.Each DOG comprises Data Products (data, AI models, and other analytics components), which can run in their own process spaces (e.g., microservices) or be executed inside the shared workspace area, with each result feeding into the lead DOG.
Think of it as a coordinated pack—there's a lead coordinating everything while specialized agents work on their own tasks, all sharing the same workspace but with their own execution areas. These agents can handle different types of data, AI models, and analytics, whether running as separate services or within the shared space. It's a systematic way to break down big problems into manageable pieces while keeping everything connected and coordinated.
We have demonstrated how multiple AI agents collaborate on complex data problems by using Data Object Graphs (DOGs). There's much more to come, so stay tuned.
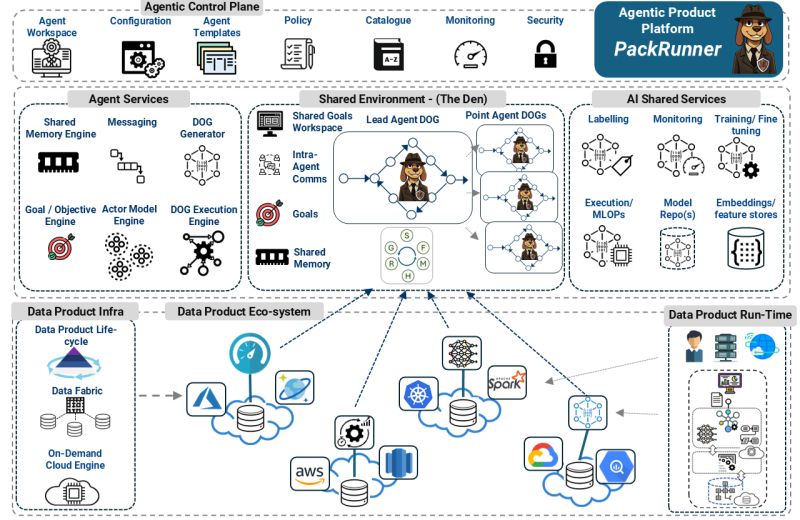
Following the discussions on DOGs, several people have inquired about the architecture supporting Agent DOGs. Introducing PackRunner, which solves key problems through coordinated, parallel execution with shared context.
Control Plane (Mission Control):
Agent Services Layer:
The Den (Shared Environment):
Utilizes an actor model for simultaneous agent process execution.
Lead Agent DOG:
Point Agent DOGs:
AI Services Integration:
Data Product Infrastructure:
When tackling a complex goal-oriented process orchestration:
This architecture effectively merges two systems—the Data Product infrastructure and the Agentic AI framework. While they address different problems and have distinct solution and architectural approaches, they coordinate seamlessly. A key tip: do not attempt to merge them into a single system.
This architecture builds upon our Data Product and AI work that has been successfully implemented across many organizations.
"Better Processes, Smarter Pack": We have been engaging in numerous conversations about our approach to business change. It's fascinating that we still rely heavily on workshops and theoretical designs when we wouldn't consider building a bridge or aircraft without first simulating it.
While working on various process transformation use cases, it has become apparent that we are effectively experimenting with digital process twins. What if we could test new processes in a safe environment before deploying them?
Using Data Object Graphs (DOGs), we can achieve this by quickly simulating process changes using interactive, executable canvases. The technology stack is intriguing and includes components like:
Instead of traditional whiteboarding, we've been prototyping processes directly on the canvas. We've encountered some failures, but these were quick and inexpensive to address—something often impossible in many cases.
The concept is straightforward:
The technology to enable this is sophisticated—creating end-to-end business processes (using DOGs) with distributed processing and AI-native integration (LLMs and Small Language Models, both local and SaaS-hosted). However, the core idea is simple: to model and reconfigure the information layer of business processes at the speed of business.

"Decisions Need DOGs to Hunt for the Truth": Agentic AI and Data Object Graphs (DOGs) can revolutionize strategic decision-making.
Decision Intelligence transforms organizational decision-making from intuition-based choices into engineered processes by combining data science, behavioral insights, and systems thinking. It aims to create repeatable frameworks that capture decision patterns, reduce biases, and continuously learn from outcomes, ultimately enabling better choices through a structured approach that balances human judgment with computational capabilities.
However, traditional decision intelligence frameworks often struggle with:
Combining Agentic AI (autonomous AI agents) with DOGs addresses these challenges in decision intelligence.
AI Agents act as specialized knowledge workers:
DOGs serve as the "neural network" connecting these agents:
The future of decision intelligence isn't just about better algorithms or more data—it's about creating an ecosystem where AI agents can collaboratively work with humans, using DOGs as their shared understanding of the world. Being able to test these out in simulations quickly, cheaply, and with low risk allows firms to "try before they buy," but it requires a new way of thinking that also integrates well with their current operations.

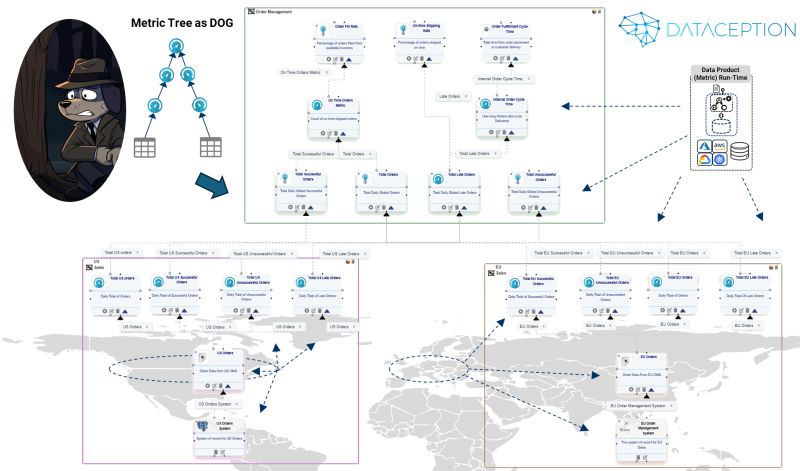
"Release the Hounds": There has been significant interest in the technical details of DOGs, so we'd like to make them concrete by anchoring them in the real world of Business Intelligence (BI) and enterprise metrics.
The core concept is a metric tree that rolls up to a business insight, represented as a Data Object Graph (DOG)—a directed graph where metrics are nodes forming an executable dependency tree.
Technical Implementation:
Every metric in our graph is a self-contained Data Product runtime, deployed as a container, carrying its own compute requirements, governance rules, Service Level Agreements (SLAs), and data quality rules. They also include a query/data processing engine that forms a distributed, virtualized Data Fabric.
These nodes know what they need, where they can run, and whom they serve, which can span cloud and on-premises infrastructure. They have service contracts with methods for filters, versioning, etc. Metrics call each other through the graph, all rolling up to the root (the topmost metric in the graph).
There are two types of metrics:
For the infrastructure, these aren't just static configurations—they're dynamic patterns that adapt as the system runs and execute where they need to, allowing for dynamic relocation (being cloud-agnostic). For example, in financial metrics, transaction processing stays close to core banking, risk calculations run in secure zones, and regulatory reporting executes where jurisdiction demands.
One can execute any part of this DOG by navigating to any node and running the graph from that point.
When metrics become graph nodes, they behave like a coordinated pack—each knowing its role but working together. Some process data near the sources, others aggregate downstream, all choreographed by the graph.
This is one use case, with metrics as the execution nodes, but the nodes could be LLMs, knowledge graphs, or any type of processing unit. This usage demonstrates the power of this approach.
The beauty lies in the ability to model and reconfigure the information layer of business processes at the speed of business (the metric tree mentioned was built and deployed in three hours).
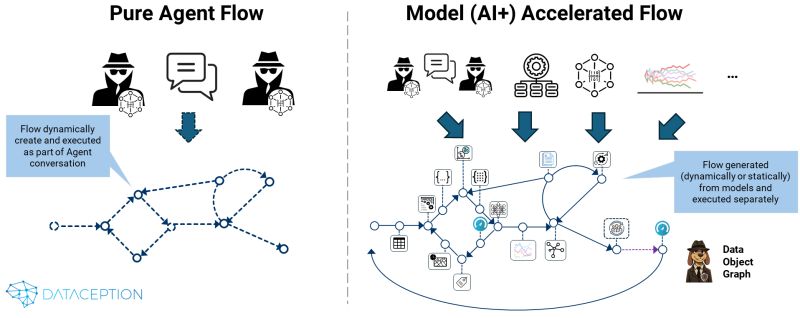
We are observing two emerging AI/agentic patterns:
Pure Agentic Workflow (PAW): Delegating entire tasks to AI agents that work autonomously. Examples include email management bots or automated customer service agents that handle inquiries end-to-end with minimal human oversight.
Model-Accelerated Workflow (MAW): Humans and AI working in close collaboration. AI agents and models amplify human capabilities by generating or augmenting more prescriptive process flows.
In PAW approaches, agents use their interactions (e.g., LLM-driven conversations) to create and execute an implicit workflow dynamically. These approaches are highly effective for many use cases, offering significant efficiency through automation. However, the probabilistic nature of these agents can be problematic for highly regulated and prescriptive workflows.
For instance, Parcha, a fintech startup, attempted to build autonomous AI agents for critical flows such as Know Your Business (KYB), Know Your Customer (KYC), and fraud detection. These use cases required accuracy, reliability, seamless integrations, and a user-friendly product experience, which can be challenging for the dynamic nature of PAW approaches.
For more predictable and prescriptive flows, MAW approaches, like our Data Object Graph (DOG), are advantageous. In our DOG methodology, we use models (AI agents, classical and generative AI, simulations, etc.) to accelerate the creation and execution of flows, which include LLMs, Small Language Models, and other algorithms as processing nodes.
Model-driven DOGs accelerate processes while providing transparency, predictability, and human input, but they may lack the dynamism that PAWs offer.
Ultimately, it's about balance, and there are variations between the two approaches. It's not a matter of choosing one over the other—currently, both are necessary in the AI and algorithmic toolkit, and it's essential to know when to use each.
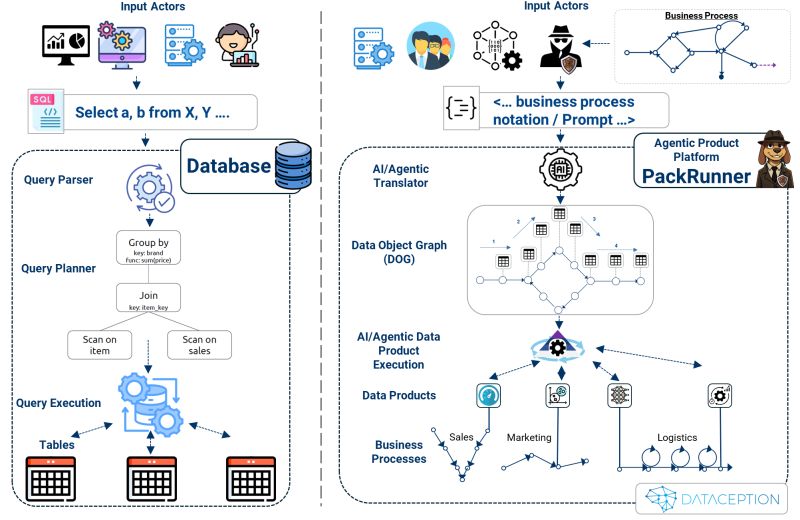
After sharing the above chapters, we've received numerous insightful questions about the fundamentals of Data Object Graphs (DOGs). To provide clarity, we'd like to draw an analogy with traditional database architecture, as the Agentic DOG process—modern AI-driven business process execution—mirrors this architecture conceptually.
Let's compare Classic Traditional Database architecture with our PackRunner Agentic Product architecture to highlight the parallels.
PackRunner orchestrates these processes across various business domains—such as Sales, Marketing, and Logistics—spanning multiple clouds and disparate infrastructures. This dynamic orchestration allows for seamless integration and execution of complex business workflows.
An intriguing aspect is how the state, represented by evolving datasets, traverses the graph. This movement alters the traditional data modeling approach, offering more flexibility and adaptability. We'll delve deeper into this topic in future discussions.
Data outputs can be returned by the last data product executed, enabling actions such as sending emails, updating transactional systems, or providing insights to BI tools.
While traditional databases typically operate on static data structures, PackRunner has the capability to create living, executable workflows. These workflows can dynamically access and orchestrate real business processes, effectively turning business logic into executable reality.
This is the essence of PackRunner's approach: leveraging Agentic Data Object Graphs to transform business intentions into actionable, dynamic processes that drive innovation and efficiency.
One of the most common concerns about AI agents involves the predictability and transparency of their decision-making processes. Traditional agent architectures often obscure their internal states within sequential memory buffers and token windows, making it challenging to understand their decision-making processes, particularly when driven by Large Language Models (LLMs).
DOG-equipped agents address this challenge through a dynamic, graph-structured memory architecture. This approach maps and records relationships between data and executable nodes (data products) in real-time, enabling transparent state tracking and context management across multiple interactions.
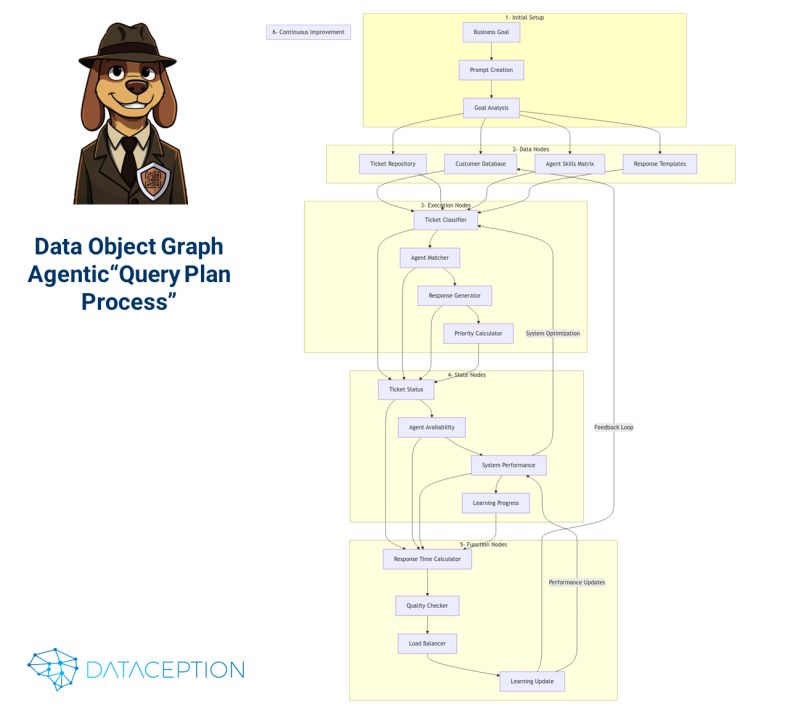
Consider how this works with a concrete business objective like "Reduce customer support response time by 50%." The system processes this through several structured phases:
The system methodically:
The system employs AI to construct its Data Object Graph with four primary node types:
A customer support system implementation demonstrates this architecture in action:
Input: "Create an AI-enhanced support system with sub-1-hour response times"
The system automatically generates a DOG with these data products arranged in three processing stages:
This implementation achieved significant measurable improvements:
The DOG approach delivers several critical advantages:
This technology is transforming how organizations handle complex operations by enabling:
The transparency and structure provided by DOGs make AI systems more manageable, predictable, and aligned with business objectives while maintaining their powerful capabilities for autonomous operation and continuous improvement.
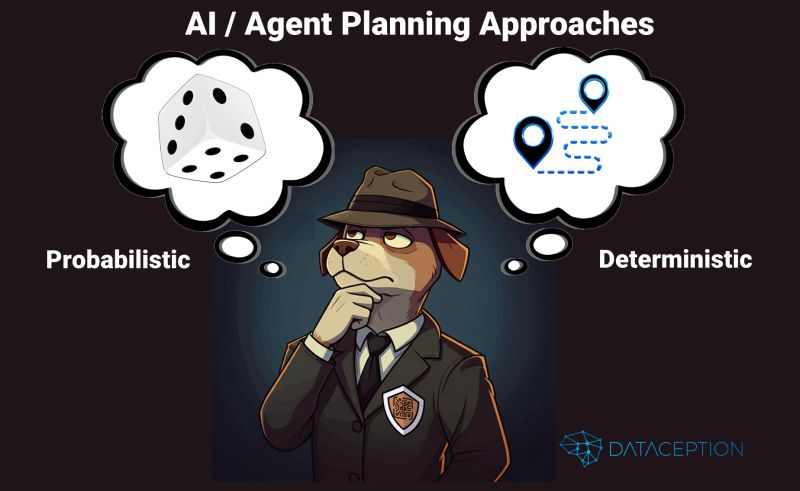
Over the weekend, I had a fascinating discussion that shed light on a critical yet often overlooked aspect of Agentic system design: the strategic choice between deterministic and probabilistic planning. This decision is fundamental to building enterprise-grade agent systems and directly impacts their performance, reliability, and adaptability.
Agent planning is the decision-making architecture that drives an agent's actions. There are two dominant approaches:
Probabilistic Planning:
This approach leverages Large Language Models (LLMs) to create plans dynamically. Probabilistic planning excels in flexibility, context-awareness, and adaptive decision-making. However, it comes with challenges:
Deterministic Planning:
This approach emphasizes precision, repeatability, and predictability through more rules-based systems. Sometimes referred to as "Agents on Rails" (thanks, Parcha!), deterministic planning is ideal for environments where consistency is critical. However, it struggles with:
The most effective enterprise-grade agent architectures don’t rely solely on one approach—they integrate both. The choice between probabilistic and deterministic planning isn’t about excluding probabilistic components like LLMs entirely; it’s about where and how you use them.
For instance, LLMs can serve as the "glue" between deterministic components, enabling dynamic adaptability while maintaining the reliability of deterministic processes. At Dataception Ltd, we employ AI/LLM-generated Data Object Graphs (DOGs) to fuse these approaches seamlessly.
Decomposition Over Delegation
Break down complex tasks into smaller, manageable pieces rather than delegating everything to a single large LLM. This improves both control and efficiency.
Match the Tool to the Risk Tolerance
Benchmark Against Reality, Not Perfection
Probabilistic systems shouldn’t be judged against ideal deterministic outcomes but rather against existing human processes, which are inherently probabilistic. Often, probabilistic outputs are "good enough" for the task—just know when they won’t be upfront to avoid costly rabbit holes.
A key strength of Data Object Graphs (DOGs) is their ability to incorporate both deterministic and probabilistic elements in a structured yet flexible way. By using DOGs, you can dynamically adapt workflows, incorporating LLMs where appropriate while grounding high-stakes processes in deterministic logic.
For example:
This hybrid architecture creates a powerful, enterprise-ready framework for Agentic systems.
The key to building robust, enterprise-grade Agentic solutions lies in leveraging LLMs and deterministic systems in harmony. By strategically choosing where to apply each approach, you can create solutions that balance precision, flexibility, and scalability.
Just as Gutenberg’s printing press democratized knowledge, AI (Generative + Agentic) is revolutionizing how we create end-to-end software and analytics. In much the same way the press allowed books to be produced quickly and distributed widely—bypassing the labor-intensive work of scribes—AI is accelerating data and technology projects at a remarkable pace.
What once took teams of developers months to build can now be prototyped in a matter of hours. At Dataception, we call this the AI Digital Twin: leveraging Generative AI and agentic methods with Data Object Graphs (DOGs) to create fully realized analytical applications—complete with user interfaces, back-end logic, and integrated data—at unprecedented speed.
Rather than replacing people, AI empowers every member of a project team to contribute at a higher level:
You may have heard the debate:
TL;DR: Both are valid. Each has its place and must be applied with an understanding of the use case and risk profile.
Ultimately, whether you choose PAW or MAW—or a hybrid of both—tools like Lovable (and, of course, our own solutions) help us rise above the data trenches. We can finally give businesses what they’ve been asking for (at least for the last 30 years): rapid, agile, and game-changing outcomes that truly align with their needs.

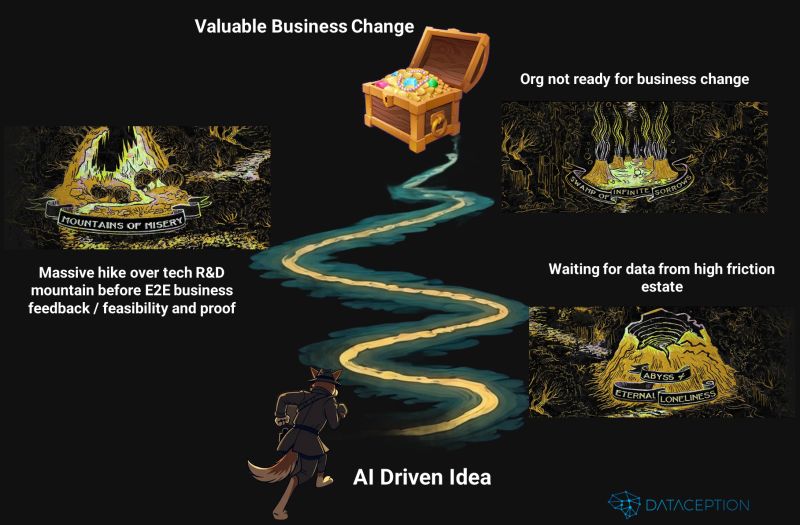
"We might get in trouble for this one." My son (and I, to be honest) love the Puss in Boots movies, and while watching the latest installment, the scene where the map conjures a nightmarish journey for Puss reminded me of many AI implementation challenges I've seen in organizations. Concept to realized business value is not always a straightforward path.
Below are three recurring challenges—and the insights we've gained—while helping organizations navigate the AI landscape quickly, cheaply, and effectively.
AI often relies on raw data, so make sure you can source it quickly—even if it’s imperfect. You won’t know the data’s value until you see it. Organizational blockers (e.g., delayed access tickets, excessive approval layers) frequently stall innovation, so streamlining this process is critical.
Key Takeaway: Don’t aim for perfectly refined data from the outset. Access raw data, run quick experiments, and refine iteratively.
AI is rarely (if ever) 100% accurate. Instead of striving for perfection, focus on fast end-to-end feedback loops that validate business impact. Rapid prototyping with digital twins—complete with user interfaces, process flows, models, and data—enables you to:
Key Takeaway: Prioritize fast, iterative delivery over large, costly programs with unclear outcomes.
Many organizations view AI as solely a data or tech initiative, creating internal friction and resistance. In reality, AI introduces business process change. Engage end users by showcasing an end-to-end business workflow, highlighting how their daily tasks benefit from AI.
Key Takeaway: Frame AI as a driver of business transformation, not just another tech project. Collaborate with business units and show tangible, user-focused value.
Success lies in simultaneously overcoming all three challenges while maintaining momentum. Organizations that can ideate → prototype → iterate rapidly at scale will see tangible ROI from AI.
With Agentic AI accelerating the entire process—and making end-to-end business change conversations unavoidable—the real question is: Are you ready for this transformation?
By addressing these common pitfalls head-on, you’ll unlock AI’s potential to turn ruff terrain into real business treasure—and hopefully avoid that cinematic horror-show journey in the process.
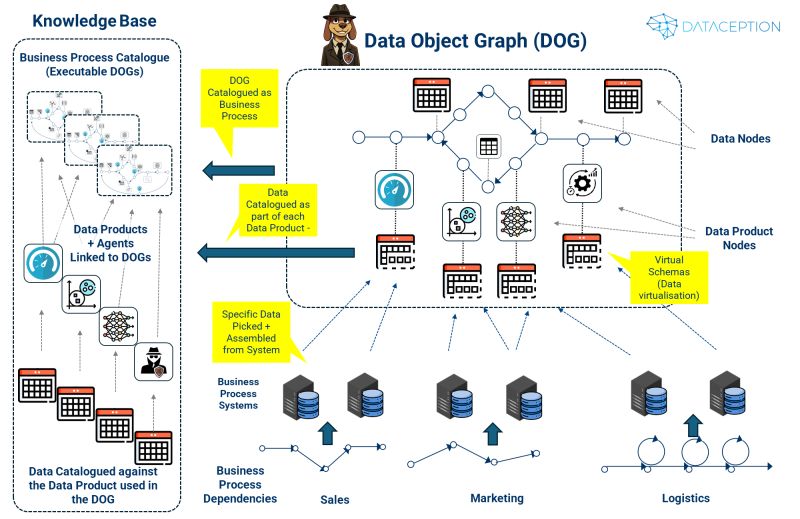
We recently highlighted a growing imperative: move from data-centric to business process-centric thinking. In practical terms, this means quickly assembling “AI Digital Twins”—end-to-end business processes (flows, components, UX, governance, etc.) that incorporate exactly the data needed, iterating in rapid cycles with business stakeholders.
Prolonged Canonical Modeling
Months or years spent creating canonical data models slows innovation, adds cost, and delays the testing of new ideas.
Delayed Business Use-Cases
Data programs can become mired in infrastructure and conceptual frameworks, delaying real end-to-end business use-cases.
‘Single Customer Record’ Complexity
Different processes often require different views of customer data, conflicting with the dream of one unified, perfect record.
Loss of Business Context
Homogenizing “data assets” can strip away contextual nuances, leading to brittle designs that break under new use-cases.
Friction for AI and Agents
AI models and agentic systems need quick, repeatable access to raw data. Rigid data pipelines hamper these evolving needs.
Instead of focusing on canonical data structures, DOGs start with business processes:
Process-Centric Approach
Rather than intricate data models, we define processes as the “connective tissue.”
Composable Components
Each process pulls in the data products—such as ML models, metrics, or AI agents—it actually needs.
Virtual Schemas
Provide flexible views without physically moving data, preserving business context and avoiding unnecessary duplication.
Direct Source Integration
Keep data in its source systems where possible; DOGs orchestrate the right data at the right time, capturing true domain knowledge.
Natural Data Relationships
Relationships form organically around business operations, rather than being forced into rigid schemas.
Using AI and LLMs, we can now prototype these processes in minutes rather than months:
As we construct end-to-end processes, we capture all assets and their linkages in a living knowledge system. Each DOG is recorded as a complete business process with its own dependencies, components, and virtual schemas—enabling on-the-fly data virtualization and continuous improvement.
Using AI, user experience canvases, and DOGs, organizations can quickly prototype, test, and refine end-to-end business processes at the speed of business. No more waiting on monolithic data projects; the data and business processes evolve together.
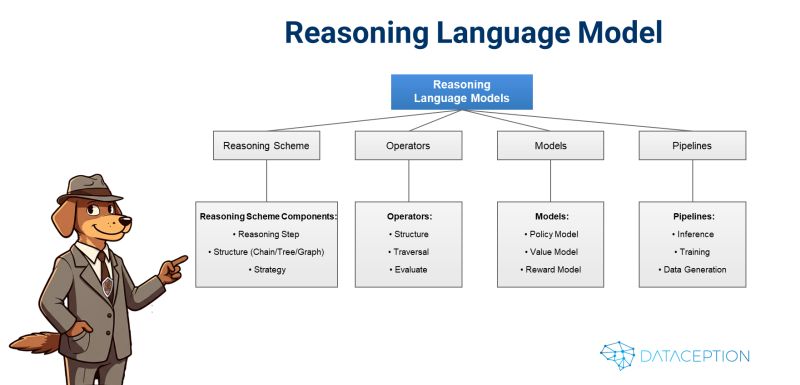
As AI continues to evolve, a new frontier is emerging—Reasoning Language Models (RLMs)—a next-generation AI approach that could redefine how machines think, solve problems, and generate insights. Unlike traditional Large Language Models (LLMs), which rely on pattern recognition and probabilistic text generation, RLMs introduce explicit, verifiable reasoning paths, moving beyond single-pass black-box processing.
While LLMs are powerful for general text generation, their lack of structured reasoning makes them unreliable for complex, multi-step problems. RLMs, on the other hand, actively explore multiple solution paths, evaluate intermediate steps, and backtrack when needed—mirroring human problem-solving.
By leveraging structured exploration using trees, chains, and graphs, combined with value and reward models, RLMs can systematically verify progress, adjust when necessary, and produce more transparent and reliable outputs. This makes them ideal for tasks such as:
RLMs offer superior reasoning, but this comes with higher computational costs and greater architectural complexity. The decision to use RLMs vs. traditional LLMs is ultimately a trade-off between advanced reasoning capabilities and resource efficiency.
1. Reasoning Scheme – The blueprint defining how AI structures its thought process:
2. Operators – The AI’s toolset for manipulating and navigating reasoning paths:
3. Models – Systems that generate, evaluate, and reward different reasoning approaches:
4. Pipelines – The workflows that orchestrate the RLM’s operations:
There’s already a great paper, "Reasoning Language Models: A Blueprint" (link https://arxiv.org/abs/2501.11223), that lays out one approach to this concept. However, at Dataception, we’ve been exploring a similar but more efficient approach—using Data Object Graphs (DOGs) to tie all these reasoning components together.
Rather than relying on massive LLMs with 100Bs of parameters, we believe we can optimize reasoning processes within DOGs, making RLMs significantly more scalable and efficient. More on that soon… but one thing is clear:
AI isn’t just getting smarter—it’s learning how to think.
I had a fantastic session with Peter Everill discussing "Quantifying Your Value: The Framework Used to Realize £100M Profit" on Kyle Winterbottom’s Orbition Group podcast (link in comments). Peter outlined a consultancy-based framework for delivering end-to-end data products that drive profit directly to the P&L—sometimes to the tune of hundreds of millions.
It all starts with the business process.
(Yes! Every Data & Analytics team should be doing this!)
A key question that came up was:
"How can LLMs accelerate this process?"
At Dataception, we’ve built a solution that does exactly that—turning simple prompts into full end-to-end business processes using Data Object Graphs (DOGs).
This is the AI Digital Twin in action—a fully executable, testable business process model.
This approach isn’t just faster—it’s safer, smarter, and more cost-effective.
By using AI Digital Twins, businesses can simulate, test, and optimize workflows in real time, unlocking true innovation without the traditional risks of large-scale digital transformation projects.
Want to see how it works? Get in touch with us if you’re interested in trying it out.
With Dataception’s DOGs (Data Object Graphs), AI really is just a walk in the park. 🚀
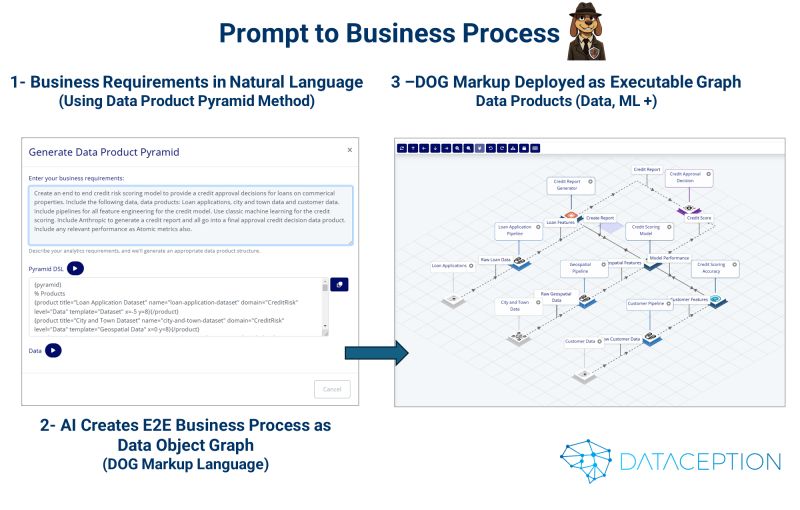
The long-standing divide between operational and analytical systems is vanishing—if not already gone.
We just used our Data Product Pyramid Gen AI tool to create transactional Data Object Graphs (DOGs) in seconds for a real-world use case. The results? A single, seamless process handling:
✅ Transactional Steps – Actions like bookings
✅ Analytical Steps – AI-powered pricing and decisioning
This is a huge leap for AI-driven business transformation.
Historically, operational data systems (handling real-time transactions) and analytical systems (for decision-making, forecasting, and reporting) have been separate worlds. This led to:
❌ Lag Between Insight & Action – Analytics were always a step behind.
❌ Complex Integration Efforts – Keeping the two in sync was a nightmare.
❌ Higher Costs & Slower Transformation – Running dual infrastructures added complexity and delays.
But with Agentic Data Object Graphs (DOGs), we can now combine both in a single, AI-driven framework—no more silos.
With DOGs, businesses can model both operational and analytical processes as a single unified execution graph.
This is not just another tech evolution—it’s a fundamental shift in how business systems operate.
We’re entering a new era where data, AI, and business operations are no longer separate conversations.
With AI Digital Twins and Agentic Data Object Graphs, organizations can finally:
It’s an amazing time to be at the nexus of Business, Tech, and AI, driving true end-to-end transformation.
If you’re still treating operational and analytical processes separately—it might be time to rethink that approach.
🚀 The future isn’t coming—it’s already here.
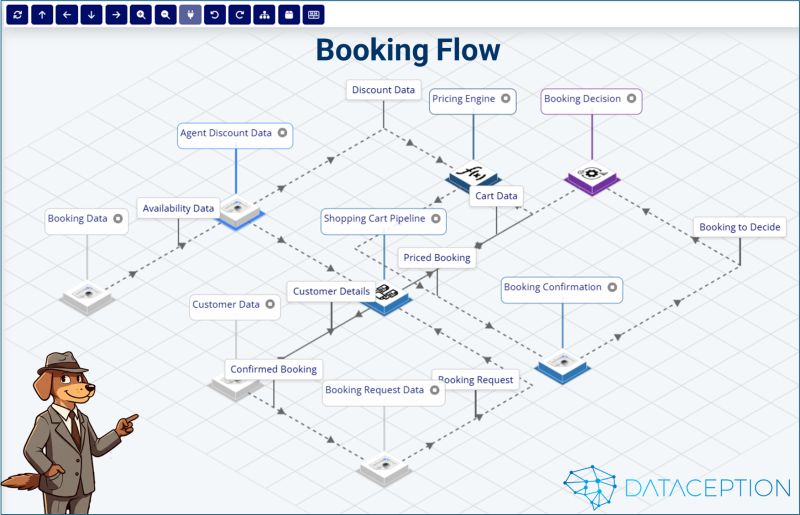
At Dataception, we’ve been working on something big—getting AI to generate Data Object Graphs (DOGs) for business processes as AI Digital Twins.
One of the biggest challenges in business transformation is bridging the gap between process design and execution. Traditionally, business processes exist as static diagrams, documents, and flowcharts—but translating those into real, working solutions has always been a manual and time-consuming effort.
With Agentic DOGs, we automate this entire process by turning traditional business workflows into machine-executable data object graphs, where each node represents a concrete data product—whether it’s:
✅ A metric
✅ A dataset
✅ An ML or GenAI model
✅ A decision engine
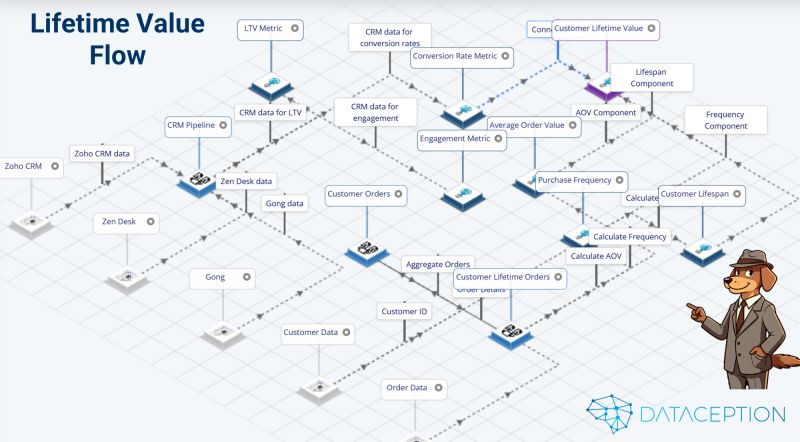
We recently mapped customer lifetime value (CLV) as a Data Object Graph. Here’s what happened:
🚀 No more manually crafting business process diagrams—everything is automated and executable.
🚀 Cross-domain processes become easier to maintain, as AI dynamically adapts to changing business needs.
🚀 Business process transformation moves from months to days, with real-time AI-driven iteration.
By using AI-generated Data Object Graphs, we’re not just automating business processes—we’re creating adaptive, intelligent AI Digital Twins that:
🔹 Bridge the gap between design and execution
🔹 Enable AI to actively participate in decision-making
🔹 Dynamically integrate with real business data in real-time
This is the next step in AI-powered business transformation, and we’re seeing incredible results already.
If you’re working on similar challenges—or just want to see this in action—let’s connect.
With Dataception's DOGs (Data Object Graphs), AI is just a walk in the park. 🐕🚀
AI implementation is proving to be a major challenge for many organizations. We’ve seen firms sink millions and years into AI projects, only to struggle with adoption and ROI.
But after years of hands-on experience, here’s what we’ve learned:
You don’t have to stop the business to integrate new AI capabilities.You just need the right process to test, iterate, and deploy—without disruption.
With Dataception's DOGs (Data Object Graphs), AI is just a walk in the park. 🚀🐕
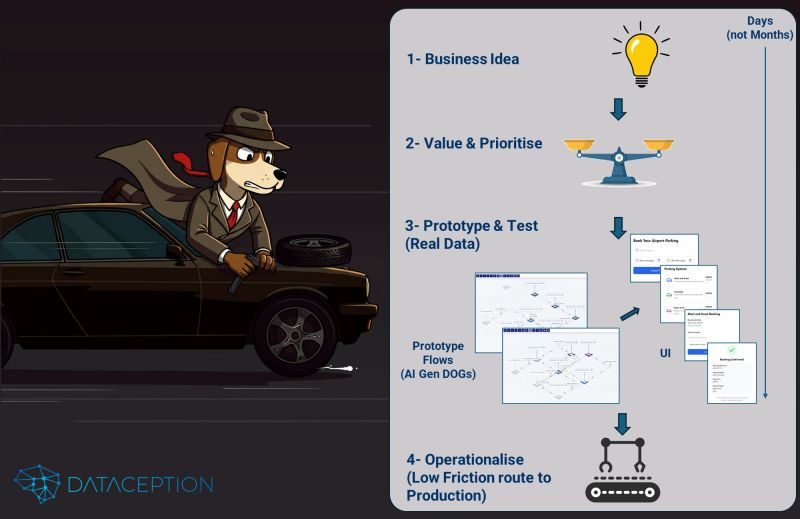
I had a fantastic discussion with Eddie Short about how GenAI is transforming the process of turning ideas into working prototypes—complete with user interfaces—in front of customers faster than ever before.
The rise of Large Language Models (LLMs) isn’t just changing how we write code—it’s revolutionizing how we bring business ideas to life.
Historically, delivering business solutions followed a slow, resource-heavy approach:
🔹 Requirement Workshops – Extensive stakeholder discussions to define needs.
🔹 UX Research & Wireframes – Building static design mockups.
🔹 Spike Solutions – Exploratory coding exercises to test feasibility.
🔹 Platform Foundations – Standing up infrastructure, security, and integrations before real development begins.
🚨 The result? Months (or longer) before the business gets:
✅ A realistic application experience
✅ Real data from enterprise systems
This is the Miner Mindset—spending time "mining raw materials" before producing something valuable.
Now, LLMs are massively accelerating this process, enabling us to build customer-facing industrial prototypes at unprecedented speed.
🔹 Idea → Working Prototype in Days – AI takes business requirements and generates an interactive prototype rapidly.
🔹 AI-Generated Business Processes – Data Object Graphs (DOGs) define end-to-end workflows, including UIs, backend logic, and data pipelines.
🔹 Real Data, Real Insights – Early-stage solutions integrate real business data, enabling immediate testing and validation.
This is the Designer Mindset—where ideas quickly become tangible, testable business solutions.
AI won’t generate a flawless solution on the first attempt—but that’s not the point.
Instead, it gets us 80% of the way there, providing a functional design that businesses can review, validate, and refine quickly.
💡 The true paradigm shift is that we can now design, test, and iterate business solutions in real time, instead of waiting months to even begin user validation.
While LLMs are game-changers, they struggle with:
🚀 The key? Knowing how to break down problems and steer AI towards the right output.
It’s no longer about writing every single line of code—it’s about:
✅ Conceptualizing business-facing systems
✅ Accelerating with AI
✅ Applying human expertise where it matters most
The ability to orchestrate AI-driven solution design is now a competitive advantage.
By shifting from Miners to Designers, we unlock the full potential of AI-assisted software development—delivering faster, smarter, and more adaptive business solutions.
With Dataception's DOGs, AI is just a walk in the park. 🚀🐕
The Data Mesh shook up the data world by rethinking how data is organized, owned, and shared across organizations. It introduced the idea of domain-driven Data Products and emphasized decentralization.
But in the AI era—Generative, Agentic, and beyond—we need to go further.
While Data Mesh laid important foundations, it stopped short of what businesses now demand:
True end-to-end use case delivery, including governance and orchestration
Integrated analytics and AI, UI/UX, and real-time business workflows
Rapid iteration and deployment, not just slow-moving architecture conversations
A next-generation approach to business-aligned, AI-powered data architecture—reimagined for the AI age.
Build enterprise-grade prototypes and deployable solutions in days, not months.
Full-stack solution templates include data, configuration, and UX
Intermediate markup enables instant business feedback loops
GenAI handles first-pass creation, while human SMEs refine and perfect
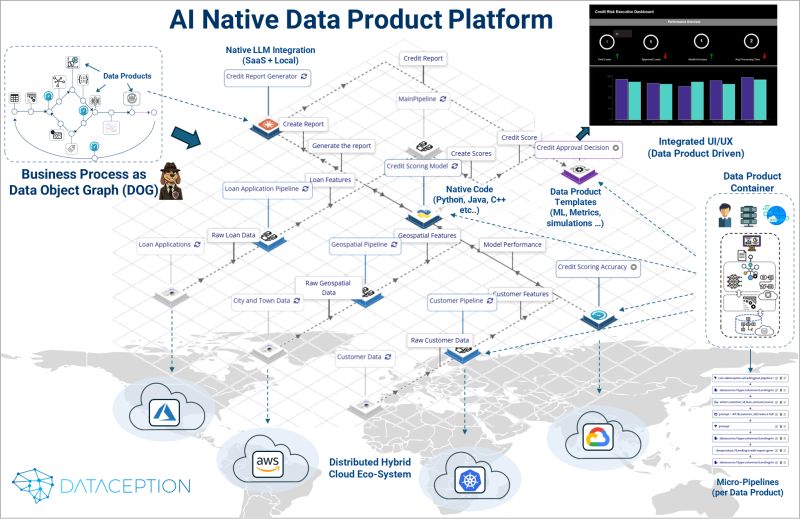
With Data Object Graphs (DOGs) at the core, business logic drives execution—not just data plumbing.
DOGs orchestrate Data Products to mirror business processes
Each Data Product includes its own UI, ML/AI models, schema, and SQL virtualization engine
Direct connectivity to enterprise data sources, minimizing integration friction
This isn’t just about plugging AI in—it’s baked into the architecture.
Native integration with LLMs (SaaS, OSS, Local), plus Classic ML and Agentic AI
Containerized Data Products that run anywhere—on any cloud, across infrastructure boundaries
AI lifecycle support: Experiment, train, fine-tune, deploy, and iterate—all within the platform
This is more than a continuation of Data Mesh—it’s a complete reimagining of how organizations build, deploy, and evolve AI-powered solutions at scale.
It’s about moving from data access to business value, from datasets to functioning applications, and from ideas to execution in days.
Want to see how it works in the real world? Get in touch.
With Dataception's Data Object Graphs, AI is just a walk in the park. 🐕🦺✨
Just as engineers simulate bridges and aircraft before construction, businesses can now simulate entire operating models using AI—before making costly changes.
With AI-powered Digital Twins, we enable organizations to prototype, simulate, and validate transformation initiatives using real data, AI models, and business-facing UIs—in days, not months.
While we still love a good whiteboarding session, static diagrams and theoretical models just don’t cut it anymore. With Data Object Graphs (DOGs), we can:
Build interactive, AI-driven simulations of full business processes
Validate ideas with real data, models, and logic
Empower business teams to test, refine, and iterate—before committing to implementation
GenAI models the end-to-end process from a simple business idea
Auto-generated on an interactive canvas (think Figma, but live and executable)
Use low/no-code tools to refine each Data Product
Bring in live data, define micro-pipelines, build models, and craft real UIs—in minutes
Each Data Product spins up as a containerized service
Plug in SQL, graph, vector databases, ML models, LLMs (local/SaaS), and more
Execute the full business process live, with real data and interactions
Prove feasibility and business value before production rollout
Collaborate directly with SMEs and process owners
Align on what works and what needs to change
🔥 4X faster time-to-delivery🔥 Massively reduced risk and cost🔥 Fail-fast capability to explore new ideas🔥 Business buy-in from day one
By simulating the end-to-end transformation journey, organizations can shift from guesswork to evidence-based design, ensuring smarter investment, stronger adoption, and faster ROI.
Real-world use cases show how this approach unlocks value rapidly, often saving months of effort and millions in spend.
With Dataception Ltd’s Data Object Graphs, AI is just a walk in the park. 🐾💼
Despite years of investment, digital transformations still fail at an alarming rate. The root causes are well-known: poor communication, ineffective data strategies, and underestimating the people side of change.
Enter AI-powered Digital Twins, built using Data Object Graphs (DOGs). This approach directly tackles the eight most common failure points in digital transformation—by simulating change before you commit to it.
Rather than forcing teams to adapt to a “new way of working,” DOGs let you simulate business changes with real data—live and interactively—so employees can see and understand the benefits before any rollout.Result: Faster adoption, reduced digital fatigue.
DOGs are one-to-one representations of business processes using actual, connected data products—not just placeholder models.Result: Eliminates transformation failure due to incomplete, siloed, or incorrect data.
Interactive canvases provide real-time documentation and modeling of how processes work—what CIOs call the "greatest risk" in transformation.Result: Living documentation that evolves with the process.
With DOGs, you can simulate and test KPIs, SLAs, and success metrics before launch.Result: Measurement frameworks that are aligned, validated, and realistic.
Simulation de-risks strategy by providing data-driven validation of new ideas.Result: Stronger executive buy-in from concept to execution.
The visual, interactive nature of the platform bridges the gap between business stakeholders and technical teams, creating a shared language.Result: Fewer miscommunications and faster alignment.
Governance can be embedded directly into each data product, enabling tailored, use-case specific controls.Result: Governance becomes a value enabler, not a blocker.
Before deploying at scale, organizations can test innovations with real user data, ensuring new capabilities enhance existing workflows, not disrupt them.Result: Higher success rates and more relevant solutions.
AI-powered Digital Twins move transformation away from theoretical whiteboards and into real-world, testable simulations—with real data, real interfaces, and real insights.
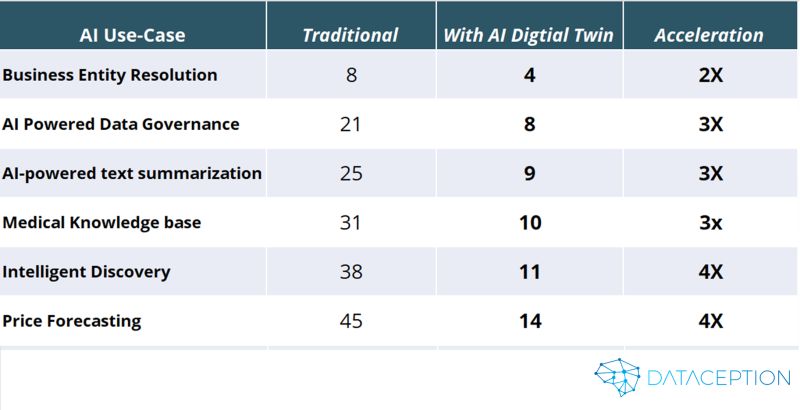
✅ Speeds up delivery by 2–5x✅ De-risks change through real-time feedback and validation✅ Drives transformation from concept to value—without the guesswork
With Dataception’s Data Object Graphs, digital transformation is no longer a shot in the dark—AI is just a walk in the park. 🐾💡

In the age of distributed data architectures—Data Mesh, data products, and decentralized ownership—one problem keeps cropping up: many architectures still fall back to centralized models. Think cross-domain schemas like 3NF, Star Schema, or Data Vault.
But that approach misses something essential: contextual business reality.
At Dataception, we use business processes (alongside proven SOA methods) as the foundation for modeling, not intermediate canonical data models. Instead of enforcing homogenization across the enterprise, we embrace context-specific entities and connect them using Data Object Graphs (DOGs)—our intelligent, AI-executable digital frameworks.
Trying to define a single “unified” version of entities like customer, order, or product across the business often creates more confusion than clarity.
For example:
A "customer" in marketing is not the same as a "customer" in fulfilment.
Each department works with a version of the entity that reflects their process needs and language.
Trying to force them into one model often leads to broken transformations and loss of meaning.
Instead of flattening everything into one model, we use DOGs to connect domain-specific data products with their unique entities and semantics.
Each function owns and models data as it makes sense for them:
📊 Marketing works with LEADS (contact info, engagement scores, campaign history)
💼 Sales uses PROSPECTS (qualification status, proposal progress)
🚚 Fulfilment operates with BUYERS (orders, payment, delivery preferences)
⚙️ Operations manages ACCOUNTS (service history, support tickets, renewals)
The Data Object Graph represents the business process that connects these entities—not by forcing a merge, but by preserving each domain’s context while enabling data to flow between them.
This model is supported by an AI-driven, searchable knowledge base that understands:
↳ Business Process
↳ Data Product
↳ Entity
↳ Attribute
Making it easy to trace how a data point connects to business value—and what happens when the process evolves.
1️⃣ Massive agility for AI and Agentic models that need on-demand, contextual data
2️⃣ Domain-specific data products reflect how the business actually operates
3️⃣ Clear ownership & governance of data products and their respective entities
4️⃣ End-to-end delivery, from idea to prototype to production
5️⃣ Flexible object graph relationships that evolve with business process change
Enterprise-wide standardization still has its place—but connecting specialized, process-bound data entities via object graphs gives you precision, speed, and adaptability.
More to come on the supporting architecture and AI use of this model in future posts.
With Dataception’s Data Object Graphs (DOGs), AI is just a walk in the park. 🐾📊

Get in touch to see how we can revolutionize the way your businesses handles data and analytics through our Rapid Predictable Data and AI Delivery model.
Explore our Services Contact Us Today
Contact Us Today