
The sharing economy has exploded in growth of the last 10 years. The sharing economy business model formalizes this desire and opens up new opportunities for engagement.
It is expected to go from generating global revenues around $15 billion in 2015 to $335 billion by 2025
It uses a model based on collaboration thanks to the capabilities enabled by data driven large scale matchmaking software platforms, which promote consumption by using Network effects
Companies that leverage data across their whole organisation can apply this model to create insight and business value way beyond their competition.
But lots of organisations still struggle in this regard.
In this series, I will outline how to businesses can accelerate their journey to this goal by building a best in class collaborative data eco system.
Firstly, why do companies continue to fall short their data and sharing journey and what is the impact?
- Companies still struggle to embed full data culture into their organisation leading to value being lost in bad data practices
- Data still, exists in silos with poor quality, creating extra operational time and cost in trying share data
- Data strategies have been underway but only achieving small incremental gains
- Cleaning and labelling the data for the machine learning training takes a lot of time and money
- Successfully deploying large scale Big Data and AI platforms in a secure and reliable fashion requires costly engineering capabilities
- Legacy IT infrastructure leaves companies to struggle to understand what data is where and in what state it's in leading to time spent in "Data Archaeology" (excavation, brushing off and careful analysis of collected data)
- Companies generally only think about data as the asset, but extra savings can be gained if one includes other types of asset e.g. machine learning models, BI dashboards, data quality rules & metadata
"51% of IT professionals report they have to work with their data for days, weeks or more, before its actionable"
– Harvard Business Review
In short, data assets are still largely only used for the business process they were originally created for and massive amounts of time (and cost) is spent trying to coerce them to work for other purposes.
Major data reuse is still a vision that a lot of organisations still struggle to get anywhere near.
Journey to a Data Sharing Culture
Given, according to various surveys, 51% of I.T. professionals are having to spend large amounts of time working on data to make it actionable and one fifth of companies are struggling to share data it's no wonder companies are slow to adopt and embed analytics into their organisations in a meaningful way.
If we can fundamentally solve these two problems then this would dramatically accelerate a firm's ability to capitalise on AI and advanced analytics
Nearly one fifth of companies have difficulty accessing data from another part of the organisation"
– Forbes
I have seen many organisations where siloed data science and data engineering teams have large challenges in producing and deploying models in production quickly.
The Data Scientists request data from the data teams, then spend time waiting to get the data after requesting it. Once received, they spend significant time wrangling, assessing and preparing the data before the model can be developed.
When they have a release candidate model they will try to serve it into production but the I.T teams may scratch their heads and say it will take a x months to deploy in our current infrastructure.
What is needed, is to shrink the non-modelling part of the whole process down to, days (ideally), if not hours
In my view, there are main four steps to achieving this:
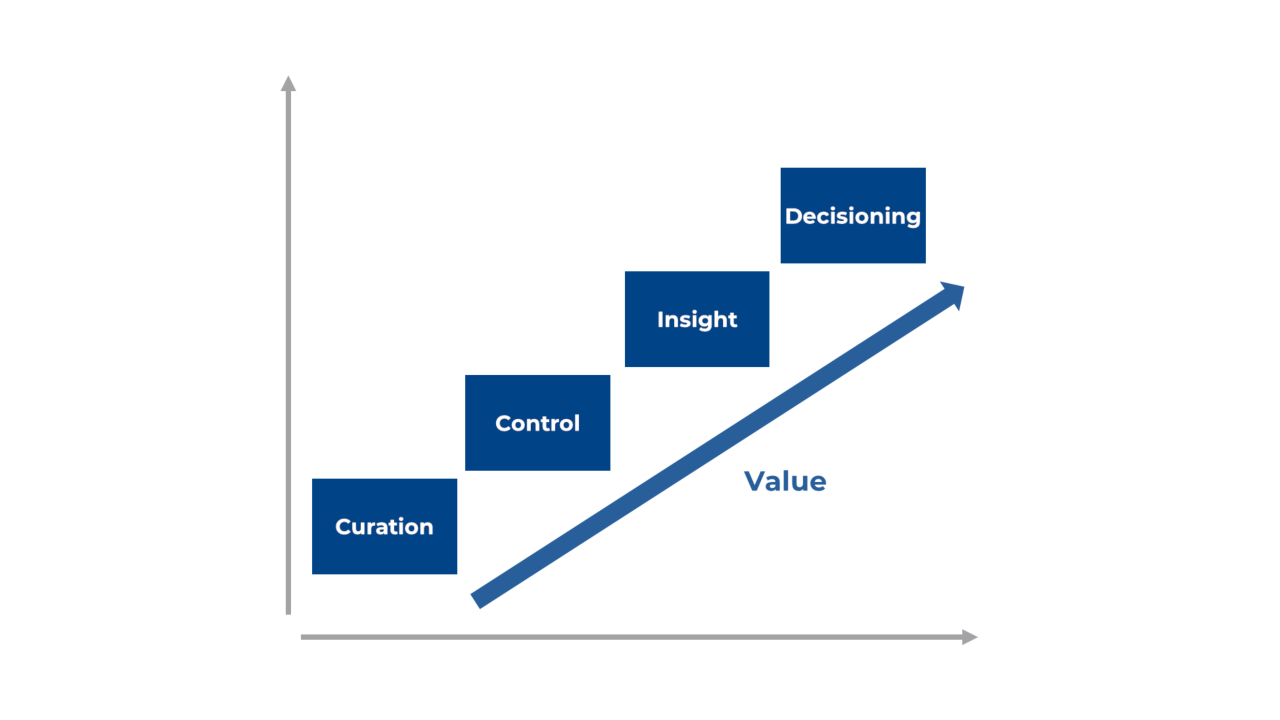
- Curation:
One needs to source, prepare data assets and make them available in a form that can is easily searchable and understandable by all types of user - Control:
The data asset needs follow good DataOps and data management practices to improve the speed and accuracy of the production of analytics. - Insight:
Analytics teams need to be able to experiment and iterate on models quickly and accurately with a known, controlled and easily accessible pool of data - Decisioning:
Data assets interaction needs to be self-service for all users, from board, to data scientists to be able to be included in all day to day business decisions.
They key to solving this underpinned by adopting the curation process from the outset. Data assets that are produced by business processes are stored, catalogued and organised so that they can be accessed by different parts of the business. This provides a solid foundation to build on.
It's about getting data assets in the hands of all of your users as quickly and with as little friction as possible.
"Low Friction Data"
It must include the I.T., support and operations functions so that new assets can be deployed in minutes in a controlled and predictable way using DataOps best practices

Consumers need to understand the data assets "state" in order to know if they are useable and useful. State includes: Lineage, data quality, business state, versioning, statistics, schema and usage patterns amongst others

Data assets need to be able to be used in iterative, fail fast and experiment based analytics development processes in order to build valuable insight models to drive business initiatives

In order to create a truly data driven culture all business users in the the companies functions are also catered for, not just data scientists and highly technical staff
To enable users to have their data assets to easily and quickly travel through their respective life-cycles DataOps needs to be employed, but this not enough. The I.T. and data infrastructure needs to do a lot of heavy lifting by having good user experience and flexible, scalable data asset execution, serving (deployment) and management functionalities.
Any solution also needs to scale, both in types and numbers of users as well as data sizes. It needs to employ easy to use (low friction) collaborative interfaces to allow all teams to be as agile as possible.
This manifests as a collaborative, globally accessible data platform that allows data assets to be easily and quickly shared, worked on, interactively, across the organisation.
Data Asset Marketplace
This is where a solution that allows users to interact with data assets in a "marketplace" setting, can solve these challenges.
I call this, unsuprisingly, the "Data Asset Marketplace".
The reason why I use the marketplace analogy is that, the way I think about it, data assets are "traded" between the producers (sellers) and consumers (buyers)
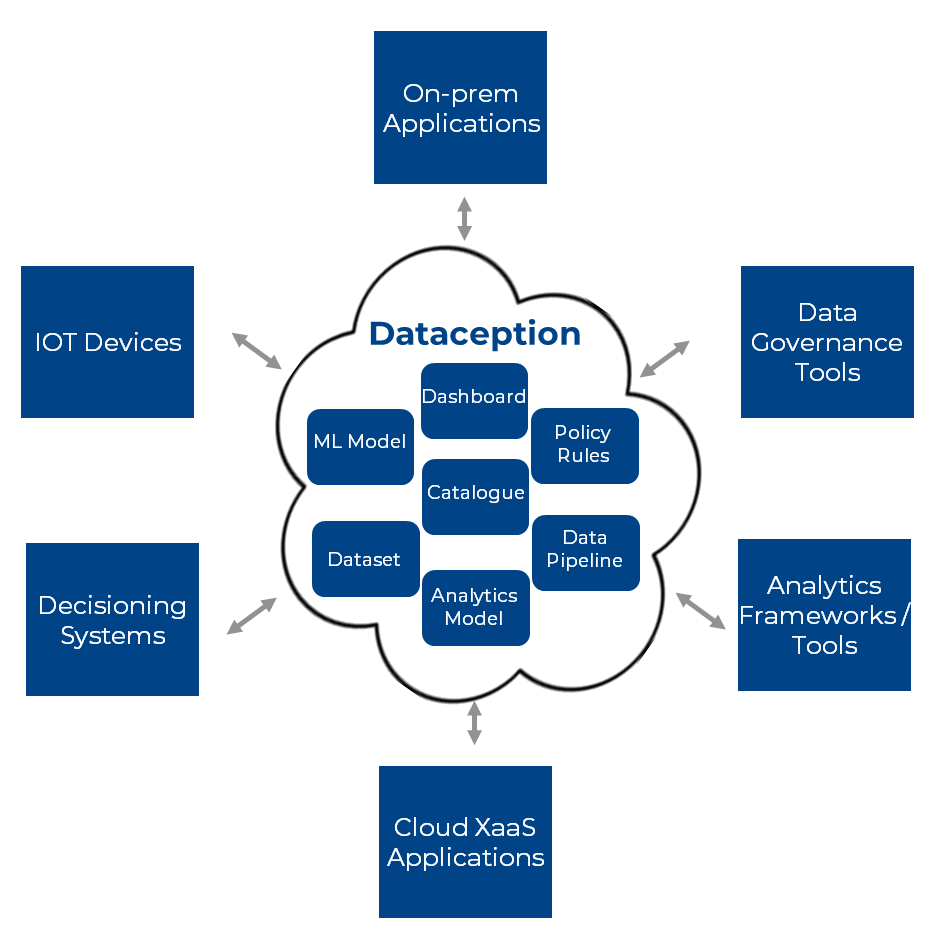
Producers create data assets as "products" i.e. they package them up in a way that allows them to be consumed by multiple consumers
The way to think of if it is, a pool of searchable data assets that can be used with the tools each user is familiar with.
Key Features include:
- The marketplace contains all data assets as technology artefacts
- It receives assets from all types of systems and technologies, from IOT devices to legacy transactional systems to data governance tools
- The marketplace leverages hybrid cloud and edge technologies. Public and private for scale and Edge for connectivity
- It includes a Business orientated meta-data repository to create a searchable catalogue of data assets along with their meta-data.
- Runs Big Data, BI and machine learning eco-system platforms and frameworks such as Spark, Python, R, BI Tools, Jupyter, Zeppelin and IDEs so that users can interact with the assets in the tool of their choosing
- Uses on-demand deployment of resources to auto-scale and be cost effective
- Supports DataOps by having easy, quick and controlled deployment of data asset run-times into production
This approach has many advantages over a traditional data lake:
- Multi-asset-type storage and distribution
The marketplace stores more than just data i.e. store variety of technology artefacts as encapsulated objects, so avoids the "we just built another data warehouse as a data lake" challenge. - Multi-technology pipelines
The marketplace can run many technologies, via containerisation. This is enables, for example, one team to build a BI dashboard and very quickly couple it to another teams' machine learning model. The end result is not just a data pipe-line but an end-to-end insight pipeline. - Unique asset sharing structure and approach
The marketplace uses a unique data and technology approach called the Synchronised View Architecture that enables a big data platform to successfully manage and run data assets on the same cloud based infrastructure - More on this in a later publication. - Collaboration and sharing workflow
Data assets and can be "checked out", manipulated and annotated and then "checked back in" in as part of an interactive collaborative workflow. - Economical and flexible infrastructure
The marketplace utilises on-demand compute and storage from hybrid cloud providers to provide isolation, scale and cost efficiency (business teams use their own resources and only pay for what they use)
So how does this type of solution work with our previous process?
- Curation
Since the Market place can store and catalogue data assets along with business state and context business, companies can easily store and distribute data assets so that consumers can quickly discover, asses and use and then publish back new or, amended, data assets. - Control
Given each data asset has information about its data quality, business state etc... consumers can quickly ascertain its relevance and usefulness - Insight
The Marketplace provides data assets with data quality and simple statistics reducing taking out many weeks of time the data scientist would have spent in data preparation and discovery - Decisioning
The self-service and low friction user experience allows all users, no matter what level of sophistication, to use data assets in their data to business processes. Thereby making it very easy to embed sophisticated analytics in day to day business functions
The Marketplace platform provides a quick, intuitive and easy life-cycle interaction process that enables business lines to to collaborate, discover, analyse, create/augment annotate and re/publish back for others to use.
One of the keys to making this successful is that the re-use aspect is baked into the development process that is used by change, analytics and IT teams.
Also, bespoke builds and vendor solutions need talk the data asset "lingua-franca" with the marketplace to share their data assets with the rest of the business.
This approach reduces the weeks and months of trying and source data, or ask for infrastructure or pipeline data lake changes, that can cause the business to either get disheartened and go off and build something themselves, or worse, give up and miss a business opportunity.
Summary
So, hopefully I have shown how by implementing a sophisticated data reuse strategy with associated data technology, an organisation can gain competitive advantage and easily embed next generation analytics into their business
The key takeaways are:
- Adopt, the curation, control, insight and decisioning steps as part of everybody's day to business.
- Treat your data as actual reusable assets, and prepare you data for reuse as part of each project implementation rather than the by-product of business process
- Invest in collaborative data infrastructure that uses the cloud to scale but can allow your teams to be agile.
i.e. An enterprise wide collaborative data asset management and run-time capability, underpinned with next generation AI, Big Data and Cloud-based technologies
Comments and feedback are really welcome and even if you want to know more, drop me a line by using social media.